Bots with QnAMaker
Introduction
Microsoft's QnAMaker service leverages an assortment of machine learning technologies and Azure services to create a knowledge base of structured question and answer pairs from a collection of text-based resources, such as a company's website. The QnA knowledge base is served as an API endpoint which takes a text prompt, like a question posed to a chatbot, and uses a series of processing and featurization algorithms to match the prompt with the best answer in the knowledge base to generate an answer. An example use case would be using QnAMaker to create a chatbot that answers questions based on your company's FAQ page.
Once created, the QnA knowledge base can be integrated directly into Chime (see the Integrating with QnAMaker wiki entry), or incorporated into a chatbot using Microsoft's Bot-Framework. QnAMaker offers a convenient automatic bot creation feature that allows users to spin up a bot for a published knowledge base and publish it as an Azure Bot Service application with just a few clicks.
An overview of QnAMaker from Microsoft can be found here
In this guide, we will first provide links to external resources that cover the creation of a basic QnAMaker knowledgebase and creating a chatbot with the knowledgebase using an Azure Bot Service. We will cover in greater depth some tips on utilizing some of QnAMaker's built in tools to improve chatbot answers, and we will provide a more in depth explanation of how QnAMaker operates under the hood.
Resources for Getting Started
Quickstart using QnAMaker Portal
Quickstart: Create, train, and publish your QnA Maker knowledge base This guide from Microsoft contains all you need to create, train, and publish your first QnAMaker knowledgebase, and to set up a bot using QnAMaker's automatic bot creation feature.
Requires an active QnAMaker Azure service. If you have not created one, log in to your Azure portal and then navigate to this page. A guide to creating and managing a QnAMaker resource can be found here.
Querying your knowledgebase
Quickstart: Get an answer from knowledge base
Once your knowledgebase is created, trained, and published, this guide will walk you through exploring and evaluating the knowledgebase using the Generate Answer API, using either cURL or Postman.
Managing your knowledgebase using SDK
Quickstart: QnA Maker client library
Microsoft provides a guide with code examples for managing your knowledgebase programatically, in your choice of C#, JavaScript, Python, Java, Go, or Ruby.
Best Practices
Best practices of a QnA Maker knowledge base
This overview of best practices contains some useful insights for getting the best results from your knowledgebase.
#Improving your Knowledgebase By now, you have created, trained, and published your first knowledgebase and created your first bot. Maybe you have queried your bot with some frequently asked questions about your company or website, and have identified some gaps in the available answers or some alternative phrasing for questions that don't register properly. Now it is time to edit your knowledgebase to make improvements.
Planning your Knowledgebase
QnAMaker works by parsing text-based inputs, including webpages and other documents, into question and answer pairs. There are two main viable approaches to planning a successful knowledgebase, and which you should choose depends on your organization's objectives and resources.
The first approach is to feed QnAMaker a small to moderate set of documents that have a question-answer like structure. A common example would be your organization's FAQ page, or a how-to guide. QnAMaker excels at parsing information with question-answer structure into a knowledgebase, and with quality inputs in this form, the need for many iterative changes to the knowledgebase will be reduced.
The second approach involves feeding QnAMaker a very, very large body of input documents, on the order of thousands or more. With a large volume of input, QnAMaker will generate a very large volume of question/answer pairs. The inclusion of more information increases the probability that a good match to a customer's query will be contained somewhere in the knowledgebase. The QnAMaker's ranking algorithm is well suited to picking out the best match from a large volume of information.
Development Cycle
For best results, the development cycle for a QnAMaker knowledgebase (see guide from Microsoft here can be described as follows:
- Create Knowledgebase and chatbot.
- Add documents and train QnAMaker.
- Test chatbot with anticipated questions.
- Refine Question/Answer pairs by managing QnAMaker knowledgebase.
- Repeat steps 2-4.
Useful Features of QnAMaker
Below is a list of features that we have found useful in creating, training, and updating QnAMaker knowledgebases.
Active Learning - Enabling QnAMaker's active learning feature will create automated knowledgebase suggestions based on interactions with users.
Multi-Turn Extraction - Enabling multi-turn extraction when training your QnAMaker knowledgebase will enable the knowledgebase to add follow-up prompts to answers. An overview of the multi-turn extraction feature can be found here In short, multi-turn extraction allows for question/answer pairs to be interpreted as a nested question hierarchy. For example, on our sample QnAMaker Knowledgebase, the search term "Features" is assigned to three different follow-up prompts.
Automatic Bot Creation - Covered in the QnAMaker quickstart guide above, QnAMaker features an integrated bot creation functionality that allows you to create an Azure Bot Service with your published knowledgebase in just a few clicks.
Persona Based Chitchat - QnAMaker provides a number of chitchat datasets with different "personalities" to smooth the flow of conversation between your bot and guests.
(Brief) Look Under the Hood
A more thorough understanding of how the QnAMaker service works, while certainly not necessary to get up and running, may be helpful for getting a grasp on the limitations and capabilities of the QnAMaker service. Knowing a bit more about how the service operates may help better inform decisions about planning, input document selection, and bot creation.
Microsoft's documentation on QnAMaker is somewhat sparse on the specifics of how the service turns a body of text into a service that generates answers based on text prompts. Fortunately, the Microsoft Team has published a paper\(^1\) that explains QnAMaker's methodology in greater depth. We will review some key points here.
System Description and Architecture
The QnAMaker Overview provides a summary of the system's architecture. Below is a flowchart that describes how the QnAMaker service fits together with the QnAMaker Azure Webservice.
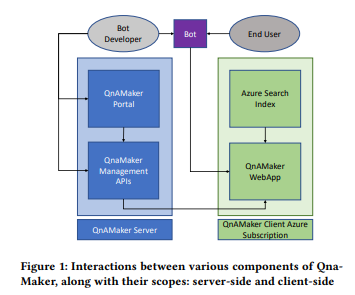
As described in the resources above, the QnAMaker Bot development process can be summarized as follows:
- Create a QnAMaker resource in Azure.
- Use management APIs or the QnAMaker interface to create, manage, update, and delete QnAMaker knowledgebases.
- Create a bot using the QnAMaker automated bot creation utility, or any other framework. Microsoft bot-framework templates are available in the documentation. Call the webapp hosted in Azure to generate answers for queries.
Text Extraction Process
After documents are provided to the QnAMaker service, question-answer pairs are extracted from the corpus of information. The extraction process is summarized as follows:
- Basic blocks from given documents (text, lines, etc.) are extracted.
- Document layout including columns, tables, lists, paragraphs, etc., are extracted using the Recursive X-Y Cut method.
- Elements tagged as headers, footers, table of contents, index, watermark, table, image, table caption, heading, heading level, and answers. 4.An Agglomerative Clustering Algorithm is used to identify a hierarchy to form an intent tree.
- Leaf nodes from the intent hierarchy form question/answer pairs. Intent trees are further augmented with entities using CRF-based (Conditional Random Field - a class of statistical modeling method often applied in pattern recognition and machine learning and used for structured prediction) sequence labeling.
Retrieval and Ranking
QnAMaker uses Azure Search index as its retrieval layer, followed by re-ranking on the top (can beuser-specified, default=10, max=100) number of results. Azure search is based on inverted indexing and TF-IDF (Term Frequency-Inverse Document Frequency) scores. TF-IDF scores help identify important terms by minimizing the weights assigned to words that appear more frequently across all documents. Azure search provides fuzzy matching based on edit-distance, which makes retrieval robust to spelling errors. Indexing can scale to millions of documents, while only up to 100 are sent to the webapp for re-ranking.
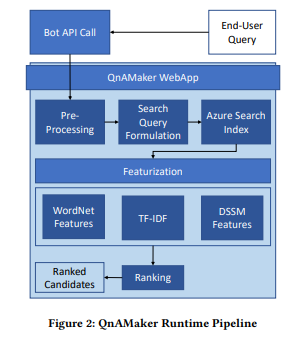
The runtime pipeline can be summarized as follows:
Pre-processing - normalizes user queries through language detection, lemmatization, checking spelling, breaking compound words, stripping stop words/junk characters.
Query formulation and Azure Search - The processed user query is run against the Azure Search index.
Featurization. Broad level features used in the ranking process include:
- WordNet - captures distance measurements between words (e.g., table -> furniture); knowledgebase word importance (local IDF's), global word importance (global IDFs) WordNet is the most important feature in the model.
- CDSSM (Convolutional Deep Structured Semantic Models) - models sentence-level similarity. Dual encoder model converts text to vectors. Microsoft's CDSSM model is trained and updated using Bing query title click-through data.
- TF-IDF (Term Frequency -Inverse Document Frequency) - disambiguates knowledgebase-specific data.
- Using model features, knowledgebase questions are ranked for fit to the user's query, and corresponding answers are returned.
Footnote
- Achraf Chalabi, Prashant Choudhari, Somi Reddy Satti, and Niranjan Nayak. 2020. QnAMaker: Data to Bot in 2 Minutes. In Companion Proceedings of the Web Conference 2020 (WWW ΓÇÖ20 Companion), April 20ΓÇô24, 2020, Taipei, Taiwan. ACM, New York, NY, USA, 4 pages. https://doi.org/10.1145/3366424. 3383525