Chat Sentiment Estimates
Introduction
Recent improvements to the Chime Reports API, and the release of a session details API, have opened up a number of new possibilities for analysis of Chime data outside of the main Chime application. Here, we will briefly explore some possible improvements to the sentiment analysis workflow made possible by these new changes. As of 4/13, this article covers:
- A basic integration of the Chime Reports API and an Azure Cognitive Services sentiment analysis endpoint.
- An integration of (2) that leverages the architecture of the ACS sentiment analysis engine to get sentiment estimates for several chats with a single Azure API call.
- An exponential weighting mechanism that weights chats closer to the end (or the beginning if so inclined) of a session more heavily.
The code in this walkthrough makes use of a codebase of helper objects. Code used in this walkthrough can be found in a ChimeV4 repo here, and a public wiki article that describes many elements of the helper codebase can be found here.
Getting Started
First, let's import some packages, including our helper codebase (import chime), and set some credential variables.
#Imports
import pandas as pd
import datetime
import numpy as np
import json
import string
import requests
import matplotlib.pyplot as plt
import chat_sentiment as chime #Importing our Chime reports API helper codebase as chime
#Setting time endpoints for Reports API query using our little timehandler function
start, end = chime.timehandler(datetime.datetime.now(), 1)
#Setting variables for initiation of the ChimeQuery class.
chime_url = 'https://instant-teams.imchime.com/Chime'
chime_api_key = 'xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx'
queueid = 'x'
start = start
end = end
reports = None
#Url and keys for sentiment extraction
ACS_url = 'xxxxxxxxxx'
ACS_sub_key = 'xxxxxxxxx'
query1 = chime.ChimeQuery(chime_url, chime_api_key, queueid, start, end, reports)
session = query1.query_session(27188)
The session details API returns information about a specified chat session in the form of a JSON tree. This tree contains the chat messages and metadata for each message and the session. It looks like this:
{
"SessionEndTime": "2021-03-29T17:02:32.8",
"AllTags": [],
"SeekerStatus": 4,
"SessionState": 4,
"state": "Completed",
"QueueID": 1,
"QueueName": "Queue Number 1",
"QueueUri": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SessionID": 27188,
"Tags": [],
"Comments": [],
"ChatMessages": [
{
"Message": "\r\nThis is a test session\r\ntest",
"StrippedMessage": "\nThis is a test session\ntest",
"SentTime": "2021-03-29T16:54:15.553",
"FirstName": "Dustin",
"LastName": "Eagar",
"metadata": null,
"SentBySeeker": true,
"SenderURI": null,
"SentByQueue": false,
"DisplayName": "Dustin Eagar",
"IsAdaptiveCard": false
},
{
"Message": {Chime html message here}",
"StrippedMessage": "Your first name:Please provide additional details about your request while I locate an expert for you:Continue",
"SentTime": "2021-03-29T16:54:16.47",
"FirstName": "Queue Number 1",
"LastName": "",
"metadata": null,
"SentBySeeker": false,
"SenderURI": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SentByQueue": true,
"DisplayName": "Queue Number 1 ",
"IsAdaptiveCard": false
},
{
"Message": "This is a test session",
"StrippedMessage": "This is a test session",
"SentTime": "2021-03-29T16:54:18.67",
"FirstName": "Dustin",
"LastName": "Eagar",
"metadata": null,
"SentBySeeker": true,
"SenderURI": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SentByQueue": false,
"DisplayName": "Dustin Eagar",
"IsAdaptiveCard": false
},
{
"Message": "{Chime html message here}",
"StrippedMessage": "Please wait while we find an agent to assist you. Our estimated wait time is 0 min 0 seconds.",
"SentTime": "2021-03-29T16:54:19.563",
"FirstName": "Queue Number 1",
"LastName": "",
"metadata": null,
"SentBySeeker": false,
"SenderURI": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SentByQueue": true,
"DisplayName": "Queue Number 1 ",
"IsAdaptiveCard": false
},
{
"Message": "{Chime html message here}",
"StrippedMessage": "Hi Dustin, we are currently locating someone to help. Please wait, we will connect you as soon as we can.Waiting: 1 | Avg Wait: 0 seconds",
"SentTime": "2021-03-29T16:54:50.34",
"FirstName": "Queue Number 1",
"LastName": "",
"metadata": null,
"SentBySeeker": false,
"SenderURI": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SentByQueue": true,
"DisplayName": "Queue Number 1 ",
"IsAdaptiveCard": false
},
...
...
...
...
],
"SessionStartTime": "2021-03-29T16:54:15.553",
"StartedRoutingUtc": "2021-03-29T16:54:18.73",
"WaitTime": "00:00:46.1565030",
"ConnectedTime": "00:02:26.1515985",
"SeekerData": [
{
"Key": "email",
"Value": "deagar@instant-tech.com"
},
{
"Key": "entryPoint",
"Value": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx"
},
{
"Key": "Session ID",
"Value": "27188"
},
{
"Key": "samaccountname",
"Value": "deagar@instant-tech.com"
},
{
"Key": "webVisitor",
"Value": "True"
},
{
"Key": "firstName",
"Value": "Dustin"
},
{
"Key": "platform",
"Value": "Win32"
},
{
"Key": "sessionGuid",
"Value": "JfmpRYTOkCM4T9fP53Xkty-f"
},
{
"Key": "question",
"Value": ""
},
{
"Key": "sip",
"Value": "679e851d-1aa3-44f6-9e0d-f70dae6fc997"
},
{
"Key": "AadObjectId",
"Value": ""
},
{
"Key": "SeekerDN",
"Value": "Dustin Eagar"
},
{
"Key": "hostname",
"Value": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx"
},
{
"Key": "lastName",
"Value": "Eagar"
},
{
"Key": "Session GUID",
"Value": "JfmpRYTOkCM4T9fP53Xkty-f"
},
{
"Key": "referrerURL",
"Value": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx"
},
{
"Key": "domainAuthenticated",
"Value": "True"
},
{
"Key": "ip",
"Value": "73.61.1.210"
},
{
"Key": "seekerOffsetMinutes",
"Value": "-240"
},
{
"Key": "locale",
"Value": ""
}
],
"Question": "\r\nThis is a test session\r\ntest",
"SessionGuid": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"SeekerRating": null,
"SeekerComment": null,
"SeekerCommentSentiment": null,
"Resolved": false,
"ExpertFullName": "Dustin Eagar",
"AssignedExpertId": 9,
"ProblemTag": "N/A",
"DomainAuthenticated": true,
"SeekerDN": "Dustin Eagar",
"SeekerEmail": "deagar@instant-tech.com",
"ReferingSite": "xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx",
"RoutingHistory": [
{
"SessionId": 27188,
"ExpertName": "Dustin Eagar",
"ExpertId": 9,
"Accepted": true,
"Timestamp": "2021-03-29T16:55:04.907",
"DeclineReason": 5,
"ExpertEmail": "deagar@instant-tech.com"
}
],
"TransferredFromSessionID": null,
"TransferredFromQueueName": "",
"TransferredToSessionID": null,
"TransferredToQueueName": null,
"TimeZone": {
"Id": "UTC",
"DisplayName": "UTC",
"StandardName": "UTC",
"DaylightName": "UTC",
"BaseUtcOffset": "00:00:00",
"AdjustmentRules": null,
"SupportsDaylightSavingTime": false
}
}
Basic Integration with ACS Sentiment Analysis
Our task is to extract the seeker chats from this JSON tree so that we can send those to Azure Cognitive services for sentiment estimation. The get_seeker_chats function takes a json tree of the form returned by the session details API and returns a list of strings, with each element containing one seeker message (stripped of html). We then can feed the results of get_seeker_chats into the get_seeker_scores function, which queries ACS for each message in turn via the chime.sentiment_query function and returns a composite average of its sentiment predictions with the help the chime.score_extraction function.
def get_seeker_chats(chats_json):
seeker_chats_list = []
for element in chats_json["ChatMessages"]:
if element["SentBySeeker"] is True:
seeker_chats_list.append(element["StrippedMessage"])
return seeker_chats_list
def get_seeker_scores(seeker_chats_list):
scores = []
for element in seeker_chats_list:
sentiment_i = chime.sentiment_query(ACS_url, ACS_sub_key, element)
score_i = chime.score_extraction(sentiment_i)
scores.append(score_i)
#print("score: "+str(score_i)+"; chat: "+element)
return scores
Here is an example of what these functions return, presented in a human readable format.
chats = get_seeker_chats(session)
scores = get_seeker_scores(chats)
for x, y in zip(scores, chats):
print("Chat: "+y+" // RawScore: "+str(x))
Chat:
This is a test session
test // RawScore: 0.515
Chat: This is a test session // RawScore: 0.515
Chat: test // RawScore: 0.55
Chat: I am having a terrible day. // RawScore: 0.0
Chat: My computer won't turn on, I lost my BTC keys, and I have just now realized the overwheliming insignificance of humanity and myself as an individual in the grand scheme of the cosmos! // RawScore: 0.01
Chat: Plugging in my computer solved all of those problems! Thank you, you are very helpful! // RawScore: 0.52
Leveraging ACS Architecture to give us more sentiment estimates cheaply
In the example above, we treated each individual seeker chat as a separate document for the purpose of getting sentiment estimates from Azure. Now, we are going to take advantage of the way that Azure returns estimates for sentiment analysis and the underlying architecture of the sentiment analysis engine to get the same number of data points with a single call to the ACS API!
When ACS is queried for estimates of sentiment for a document, it returns a JSON tree containing confidence scores for "positive", "neutral", and "negative" sentiment for the entire document, and also for each sentence contained within the document. It looks like this.
{
"documents": [
{
"id": "1",
"sentiment": "negative",
"confidenceScores": {
"positive": 0.01,
"neutral": 0.0,
"negative": 0.99
},
"sentences": [
{
"sentiment": "negative",
"confidenceScores": {
"positive": 0.01,
"neutral": 0.0,
"negative": 0.99
},
"offset": 0,
"length": 182,
"text": "My computer wont turn on, I lost my BTC keys, and I have just now realized the overwheliming insignificance of humanity and myself as an individual in the grand scheme of the cosmos!"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
For each object we wish to estimate sentiment for, our chime.score_extraction function takes the expectation of object sentiment by taking a composite average of the positive, neutral, and negative confidence scores and mapping it to the [0, 1] interval on the real line.
Here, we will repackage the list of seeker chats from our chat session so that each separate chat forms a punctuated "sentence". This way, we can use a single API call to get sentiment estimates for an entire conversation.
#Get seeker chat scores in one query to ACS by bundling chats via punctuation marks.
def combine_chat_payload(seeker_chats_list):
"""
Takes a list of strings and concatenates them in (declarative) sentence form.
"""
chats_doc = ""
for i in seeker_chats_list:
stripped_chat = i.translate(str.maketrans('', '', string.punctuation))
chats_doc = chats_doc+stripped_chat+". "
return chats_doc
def extract_combined_scores(combined_score_json):
"""
Takes the sentiment estimates JSON from a query to ACS using the combined chat payload document and extracts
scores for each 'sentence'. Extracting scores this way allows the use of one API call to get sentiment estimates
of all seeker chats from a session.
"""
scores = []
for chat in combined_score_json["documents"][0]["sentences"]:
chat_scores = chat["confidenceScores"]
score_estimate = chat_scores['positive'] + .5*chat_scores['neutral']
scores.append(score_estimate)
return scores
# Some example calls of these functions
# combined_chats = combine_chat_payload(get_seeker_chats(session))
# print(combined_chats)
# combined_scores_json = chime.sentiment_query(ACS_url, ACS_sub_key, combined_chats)
# print(combined_chats)
# print(extract_combined_scores(combined_scores_json))
A (very) brief explanation of why we can do this is in order.
Azure and other sentiment analysis models use a so-called "bag of words" approach to take an input of a natural language sentence and estimate its sentiment. This means that the sentence is treated as a collection of its component word unigrams ("hello") , and sometimes word bigrams ("help me") and trigrams ("I need help"), ordered sequences of two and three words respectively. The input sentence is vectorized (treated as a vector of counts of its component words) and compared against sentence vectors of a labelled training set.
What this means for us is that other, more complex sentence structure does not matter for the purpose of estimating document sentiment. We can therefore strip the punctuation from each message, and re-punctuate it in a manner that will make Azure interpret each individual chat as a "sentence" for the purpose of returning an estimate. A more detailed explanation of the bag of words model can be found here.
To demonstrate that these approaches return similar results, we let's estimate sentiment for messages from a small sample of chats. We'll use some helper functions to facilitate iterating over a set of chats.
def get_scores_individually(chime_query, session_id):
session = chime_query.query_session(session_id)
seeker_chats = get_seeker_chats(session)
scores = get_seeker_scores(seeker_chats)
return scores
def get_scores_batched(chime_query, session_id):
session = chime_query.query_session(session_id)
seeker_chats = get_seeker_chats(session)
combined_chats = combine_chat_payload(seeker_chats)
scores = extract_combined_scores(chime.sentiment_query(ACS_url, ACS_sub_key, combined_chats))
return scores
#A manually generated list of chat sessions for our test. These could also be generated via a session details report
session_list = [28992, 28993, 28994, 28995, 28996, 28997]
df = pd.DataFrame()
df["session_id"] = session_list
df['Sentiment_indiv'] = df['session_id'].apply(lambda x : get_scores_individually(query1, x)).apply(lambda x: np.array(x))
df['Sentiment_batched'] = df['session_id'].apply(lambda x : get_scores_batched(query1, x)).apply(lambda x: np.array(x))
df['Total_diff'] = abs(df['Sentiment_indiv']-df['Sentiment_batched']).apply(lambda x : np.sum(x))
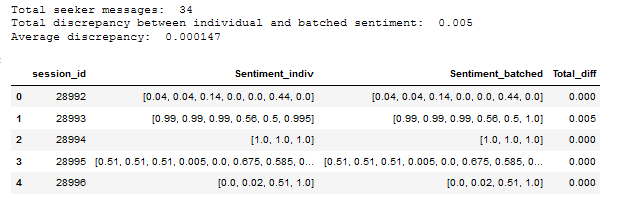
print("Total seeker messages: ", df['Sentiment_indiv'].apply(lambda x : len(x)).sum())
print("Total discrepancy between individual and batched sentiment: ", np.round(df['Total_diff'].sum(), 6))
print("Average discrepancy: ", np.round((df['Total_diff'].sum()/df['Sentiment_indiv'].apply(lambda x : len(x)).sum()), 6))
df.head()
The output looks like this:
Exponential Weighting for Chats
To this point, when considering the "average sentiment" for seeker chats throughout a chat session, we have estimated sentiment for each individual message and taken a simple average to produce a sentiment estimate. In the context of measuring agents' effectiveness at making seekers happier by solving their problems, this approach may not provide the best performance metric. The simple average does not capture change in guests' sentiment throughout the course of the chat session. Many guests are likely dissatisfied at the beginning of their chat sessions, and measuring how dissatisfied guests are before making contact with an agent tells us little about agents' effectiveness.
A possible alternative approach is to take an exponentially weighted average of sentiment estimates for each message, with messages closer to the end of the conversation (after the agent has had a chance to help fix the seeker's issue) weighted more heavily.
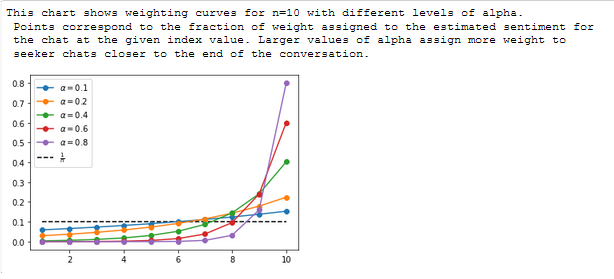
We can control the strength of this weight front-loading by setting the parameter \(\alpha\) between 0 and 1, with values closer to 1 giving more weight to chats closer to the end of the conversation.
These weights are determined by:
$$\omega_i = \frac{(1-\alpha)^{(n-i)}}{\sum_^n (1-\alpha)^i} $$
where \(\omega_i\) is the weight assigned to the chat at position \(i\), \(\alpha\) is our scaling constant with \((0 \lt \alpha \lt 1)\), and \(n\) is the number of seeker chats to average over.
Implemented in python, it looks like this.
def exp_weighting_function(i, alpha):
"""
Helper function that generates a vector of exponentially decaying weights, with
values toward the end of the vector being weighted more heavily. Weights are normalized
so that they sum to 1.
Params:
i - length of weight vector
alpha - scaling factor, 0 < alpha <= 1. Higher values will weight values toward the end more heavily.
The value chosen for alpha is roughly equal to (slightly less due to normalization) the fraction of weight
afforded to the most recent value.
"""
weights = (1-alpha)**np.arange(i)[::-1]
weights /= weights.sum()
#print("Exponential weights: ", weights)
return weights
#This sample code returns a vector of exponential weights generated by our weighting function.
x = exp_weighting_function(i=6, alpha=.2)
print("Weights: ", x)
Weights: [0.0888195 0.11102437 0.13878047 0.17347558 0.21684448 0.2710556 ]
Extending one step further, here is a function that takes an average of a vector of inputs, with a parameter input to weight those inputs exponentially by a specified factor \(\alpha\).
def get_average_score(scores_list, ExpWeighting=False, alpha=.2):
"""
This function takes a list of scores and returns either a simple or
exponentially weighted average.
"""
def weighting_function(i, alpha):
"""
Helper function that generates a vector of exponentially decaying weights, with
values toward the end of the vector being weighted more heavily. Weights are normalized
so that they sum to 1.
Params:
i - length of weight vector
alpha - scaling factor, 0 < alpha <= 1. Higher values will weight values toward the end more heavily.
The value chosen for alpha is roughly equal to (slightly less due to normalization) the fraction of weight
afforded to the most recent value.
"""
weights = (1-alpha)**np.arange(i)[::-1]
weights /= weights.sum()
#print("Exponential weights: ", weights)
return weights
if ExpWeighting == True:
scores_arr = np.array(scores_list)
weight_array = weighting_function(len(scores_list), alpha)
exp_weighted_avg = np.dot(scores_arr, weight_array.T)
return exp_weighted_avg
else:
mean_score = np.mean(scores_list)
return mean_score
Here is an example of how this function can be used to weight a sentiment estimate average for a conversation for different values of \(\alpha\).
chats = get_seeker_chats(session)
scores = get_seeker_scores(chats)
for x, y in zip(scores, chats):
print("Chat: "+y+" // RawScore: "+str(x))
print("\n \n")
print("Getting seeker chats and sentiment score estimates with simple average:")
example_avg = get_average_score(get_seeker_scores(get_seeker_chats(session)))
print("Simple average of scores: "+str(example_avg))
print("\n \n")
print("Getting seeker chats and sentiment score estimates with exponentially weighted averages: ")
alpha_list = [.1, .2, .4, .6, .8]
for alpha in alpha_list:
weighted_score = get_average_score(scores, ExpWeighting=True, alpha=alpha)
print(f"Alpha = {alpha} : Weighted Score = {weighted_score}")
Chat:
This is a test session
test // RawScore: 0.515
Chat: This is a test session // RawScore: 0.515
Chat: test // RawScore: 0.55
Chat: I am having a terrible day. // RawScore: 0.0
Chat: My computer won't turn on, I lost my BTC keys, and I have just now realized the overwheliming insignificance of humanity and myself as an individual in the grand scheme of the cosmos! // RawScore: 0.01
Chat: Plugging in my computer solved all of those problems! Thank you, you are very helpful! // RawScore: 0.52
Getting seeker chats and sentiment score estimates with simple average:
Simple average of scores: 0.35166666666666674
Getting seeker chats and sentiment score estimates with exponentially weighted averages:
Alpha = 0.1 : Weighted Score = 0.3354847201739803
Alpha = 0.2 : Weighted Score = 0.3223662069563709
Alpha = 0.4 : Weighted Score = 0.3153490870032224
Alpha = 0.6 : Weighted Score = 0.3480200501253133
Alpha = 0.8 : Weighted Score = 0.42193804403481827